
Изучение 26 методов анализа больших данных: часть 1

Изучение 26 методов анализа больших данных: часть 1
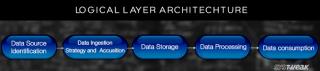
В моем последнем посте мы обсуждали анализ бизнес-проблемы и основные шаги по проектированию архитектуры больших данных. Сегодня я собираюсь поговорить о различных уровнях архитектуры больших данных и их функциях.
Логические уровни эталонной архитектуры больших данных
Основная идея архитектуры больших данных состоит в том, чтобы задокументировать правильную основу архитектуры, инфраструктуры и приложений. Следовательно, это позволяет предприятиям более эффективно использовать большие данные в повседневной жизни.
Он создается проектировщиками / архитекторами больших данных перед физической реализацией решения. Создание архитектуры больших данных обычно требует понимания бизнеса / организации и ее потребностей в больших данных. Как правило, архитектуры больших данных определяют аппаратные и программные компоненты, необходимые для реализации решения для больших данных. Документы по архитектуре больших данных могут также описывать протоколы для обмена данными, интеграции приложений и информационной безопасности.
Дополнительная информация: Руководство по аналитике больших данных для новичков
Это также влечет за собой взаимосвязь и организацию существующих ресурсов для удовлетворения потребностей в больших данных.
Ниже приведены логические уровни эталонной архитектуры:
Профилирование источника - один из самых важных шагов в выборе архитектуры или больших данных. Он включает в себя определение различных исходных систем и их категоризацию в зависимости от их природы и типа.
Вопросы, которые следует учитывать при профилировании источников данных:
Прием данных - это извлечение данных из вышеупомянутых источников. Эти данные хранятся в хранилище, а затем преобразуются для дальнейшей обработки.
Следует учитывать:
Следует иметь возможность хранить большие объемы данных любого типа и масштабироваться при необходимости. Мы также должны учитывать количество IOPS (операций ввода-вывода в секунду), которое он может обеспечить. Распределенная файловая система Hadoop является наиболее часто используемой средой хранения в мире больших данных, другие - хранилища данных NoSQL - MongoDB, HBase, Cassandra и т. Д.
Что следует учитывать при планировании методологии хранения:
Многократно увеличился не только объем хранимых данных, но и их обработка.
Ранее часто используемые данные хранились в динамической оперативной памяти. Но теперь он хранится на нескольких дисках на нескольких машинах, подключенных через сеть из-за большого объема. Таким образом, вместо того, чтобы собирать блоки данных для обработки, модули обработки переносятся на большие данные. Таким образом, значительно сокращается сетевой ввод-вывод. Методология обработки определяется бизнес-требованиями. Его можно разделить на пакетный, в реальном времени или гибридный на основе SLA.
Этот уровень потребляет вывод, предоставляемый уровнем обработки. Различные пользователи, такие как администратор, бизнес-пользователи, поставщик, партнеры и т. Д., Могут использовать данные в разных форматах. Результат анализа может использоваться механизмом рекомендаций, или бизнес-процессы могут запускаться на основе анализа.
Различные формы потребления данных:
Читайте также: Большие данные: кошмар будущего?
Функциональные уровни архитектуры больших данных:
Может быть еще один способ определения архитектуры, то есть через разделение функциональности. Но категории функциональности могут быть сгруппированы вместе в логический уровень эталонной архитектуры, поэтому предпочтительной архитектурой является архитектура, созданная с использованием логических уровней.
Уровни, основанные на функциональных возможностях, выглядят следующим образом:
В эту категорию следует включить анализ всех источников, из которых организация получает данные и которые могут помочь организации в принятии ее будущих решений. Перечисленные здесь источники данных не зависят от того, являются ли данные структурированными, неструктурированными или частично структурированными.
Прежде чем вы сможете хранить, анализировать или визуализировать свои данные, вам нужно их иметь. Извлечение данных заключается в том, чтобы взять что-то неструктурированное, например веб-страницу, и превратить это в структурированную таблицу. После того, как вы его структурируете, вы можете манипулировать им всевозможными способами, используя инструменты, описанные ниже, чтобы найти идеи.
Основная необходимость при работе с большими данными - думать, как их хранить. Отчасти большие данные получили звание «БОЛЬШИХ», потому что их стало слишком много для традиционных систем. Хороший поставщик хранилища данных должен предлагать вам инфраструктуру для запуска всех других аналитических инструментов, а также место для хранения и запроса ваших данных.
Предварительно необходимый шаг перед тем, как мы действительно начнем добывать данные для понимания. Всегда рекомендуется создавать чистый, хорошо структурированный набор данных. Наборы данных могут иметь любую форму и размер, особенно если они поступают из Интернета. Выберите инструмент в соответствии с вашими требованиями к данным.
Интеллектуальный анализ данных - это процесс обнаружения информации в базе данных. Цель интеллектуального анализа данных - принимать решения и делать прогнозы на основе имеющихся у вас данных. Выберите программное обеспечение, которое дает вам лучшие прогнозы для всех типов данных и позволяет создавать собственные алгоритмы для анализа данных.
В то время как интеллектуальный анализ данных - это просеивание ваших данных в поисках ранее нераспознанных шаблонов, анализ данных заключается в разбивке этих данных и оценке воздействия этих шаблонов с течением времени. Аналитика заключается в том, чтобы задавать конкретные вопросы и находить ответы в данных. Вы даже можете задать вопросы о том, что будет в будущем!
Визуализации - это яркий и простой способ передать сложные аналитические данные. И что самое приятное, большинство из них не требует программирования. Компании, занимающиеся визуализацией данных, оживят ваши данные. Отчасти задача любого специалиста по обработке данных - донести информацию, полученную на основе этих данных, до остальной части вашей компании. Инструменты могут помочь вам создавать диаграммы, карты и другую подобную графику на основе ваших аналитических данных.
Платформы интеграции данных являются связующим звеном между каждой программой. Они связывают различные выводы инструментов с другим программным обеспечением. Вы можете поделиться результатами своих инструментов визуализации прямо на Facebook с помощью этих инструментов.
В вашей карьере в области данных будут времена, когда инструмент просто не справится. Хотя современные инструменты становятся все более мощными и простыми в использовании, иногда лучше просто написать их самостоятельно. Существуют разные языки, помогающие вам в различных аспектах, таких как статистические вычисления и графика. Эти языки могут работать в качестве дополнения к программному обеспечению интеллектуального анализа данных и статистике.

При проектировании архитектуры больших данных необходимо помнить следующее:
Я знаю, что вы подумаете о различных инструментах, которые можно использовать для создания полноценного решения для больших данных. Что ж, в моих следующих статьях о больших данных я расскажу о некоторых лучших инструментах для решения различных задач в архитектуре больших данных .
Изучение 26 методов анализа больших данных: часть 1
Многие из вас знают Switch, который выйдет в марте 2017 года, и его новые функции. Для тех, кто не знает, мы подготовили список функций, которые делают «Switch» обязательным гаджетом.
Вы ждете, когда технологические гиганты выполнят свои обещания? проверить, что осталось недоставленным.
Прочтите блог, чтобы узнать о различных уровнях архитектуры больших данных и их функциях самым простым способом.
Прочтите это, чтобы узнать, как искусственный интеллект становится популярным среди небольших компаний и как он увеличивает вероятность их роста и дает преимущество перед конкурентами.
CAPTCHA стало довольно сложно решать пользователям за последние несколько лет. Сможет ли он оставаться эффективным в обнаружении спама и ботов в ближайшем будущем?
По мере того, как наука развивается быстрыми темпами, принимая на себя большую часть наших усилий, также возрастает риск подвергнуться необъяснимой сингулярности. Прочтите, что может значить для нас необычность.
Что такое телемедицина, дистанционное здравоохранение и их влияние на будущее поколение? Это хорошее место или нет в ситуации пандемии? Прочтите блог, чтобы узнать мнение!
Возможно, вы слышали, что хакеры зарабатывают много денег, но задумывались ли вы когда-нибудь о том, как они зарабатывают такие деньги? Давайте обсудим.
Недавно Apple выпустила macOS Catalina 10.15.4, дополнительное обновление для исправления проблем, но похоже, что это обновление вызывает больше проблем, приводящих к поломке компьютеров Mac. Прочтите эту статью, чтобы узнать больше





